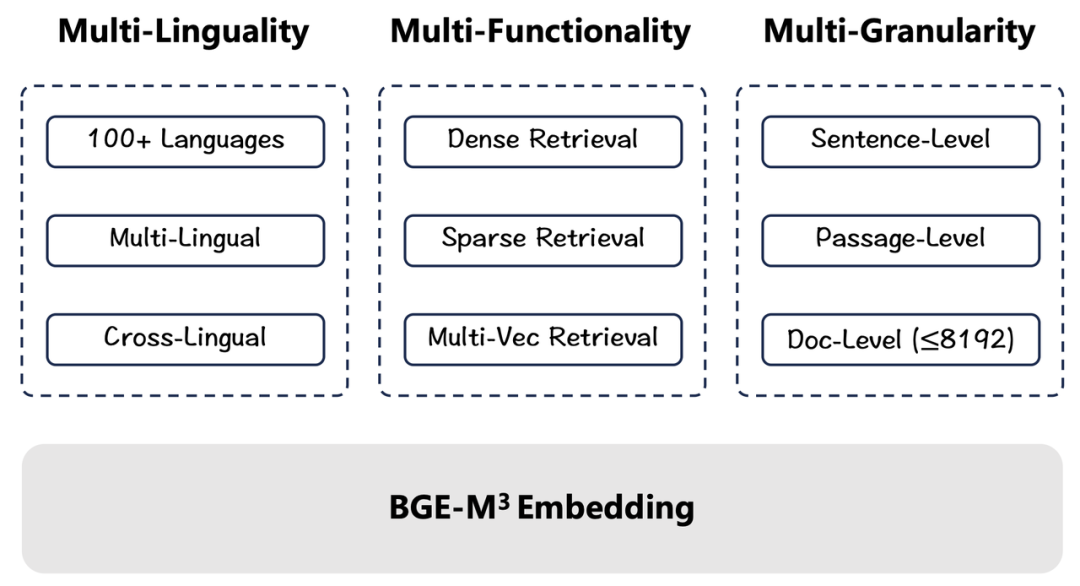
- BGE-M3支持超过100种语言的语义表示及检索任务,多语言、跨语言能力全面领先(Multi-Lingual)
- BGE-M3最高支持8192长度的输入文本,高效实现句子、段落、篇章、文档等不同粒度的检索任务(Multi-Granularity)
- BGE-M3同时集成了稠密检索、稀疏检索、多向量检索三大能力,一站式支撑不同语义检索场景(Multi-Functionality)
语义向量模型(Embedding Model)是语言模型生态体系中的重要组成部分,这一技术被广泛应用于搜索(Search)、问答(QA)、大语言模型检索增强(RAG)等应用场景之中。智源 BGE(BAAI General Embedding)模型自去年8月发布后广受好评,被开源爱好者集成至 LangChain、Llama_index 等项目,全球下载量已达713万次。近日,智源发布了BGE家族新成员——通用语义向量模型BGE-M3,支持超过100种语言,具备领先的多语言、跨语言检索能力,全面且高质量地支撑“句子”、“段落”、“篇章”、“文档”等不同粒度的输入文本,最大输入长度为 8192,并且一站式集成了稠密检索、稀疏检索、多向量检索三种检索功能,在多个评测基准中达到最优水平。BGE-M3是首个集多语言(Multi-Linguality)、多粒度(Multi-Granularity)、多功能(Multi-Functionality)三大技术特征于一体的语义向量模型,极大提升了语义向量模型在现实世界的可用性。目前,BGE-M3已向社区全面开源并支持免费商用许可。↓ 相关链接
https://github.com/FlagOpen/FlagEmbedding
https://huggingface.co/BAAI/bge-m3
下图是与mE5(Best Baseline)以及OpenAI近期发布的向量模型API的评测对比。整体来看,采用三种方式联合检索的BGE-M3(ALL)在三项评测中全面领先,而 BGE-M3(Dense)稠密检索在多语言、跨语言检索中具有明显优势。

三个公开数据集上评测:多语言(Miracl),跨语言(MKQA),长文档搜索(NarrativeQA)
OpenAI-emb-3 评测结果来自其官方博客,其余为智源团队自测BGE-M3 模型亮点
1. 多语言(Multi-Linguality)
BGE-M3训练集包含100+种以上语言,既包含每种语言内部的语义匹配任务(Language X to Language X),又包含不同语言之间的语义匹配任务(Language X to Language Y)。丰富且优质的训练数据帮助BGE-M3建立了出色的多语言检索(Multi-Lingual Retrieval)与跨语言检索能力(Cross-Lingual Retrieval)。2. 多功能(Multi-Functionality)不同于传统的语义向量模型,BGE-M3既可以借助特殊token [CLS]的输出向量用以来完成稠密检索(Dense Retrieval)任务,又可以利用其他一般性token的输出向量用以支持稀疏检索(Sparse Retrieval)与多向量检索(Multi-vector Retrieval)。三种检索功能的高度集成使得BGE-M3可以一站式服务不同的现实场景,如语义搜索、关键字搜索、重排序。同时,无需使用多个模型进行多个推理,BGE-M3一次推理就可以得到多个不同模式的输出,无需额外开销,并能高效支持混合检索,联合三种检索模式可获得更加精准的检索结果。3. 多粒度(Multi-Granularity)
BGE-M3目前可以处理最大长度为8192 的输入文本,极大地满足了社区对于长文档检索的需求。在训练BGE-M3时,智源研究员在现有长文本检索数据集的基础之上,通过模型合成的方式获取了大量文本长度分布多样化的训练数据。与此同时,BGE-M3通过改进分批(batch)与缓存(cache)策略,使得训练过程具备足够高的吞吐量与负样本规模,从而确保了训练结果的质量。基于数据与算法双层面的优化处理,BGE-M3得以高质量的支持“句子”、“段落”、“篇章”、“文档”等不同粒度的输入文本。BGE系列模型隶属于智源 FlagEmbedding 开源项目。FlagEmbedding 聚焦于检索增强LLM领域,目前包括以下子项目:
Long-Context LLM: Activation Beacon
Fine-tuning of LM : LM-Cocktail
Dense Retrieval: LLM Embedder, BGE Embedding
Reranker Model: BGE Reranker
Benchmark: C-MTEB
BGE-M3 在多项评测中全面领先
1. 多语言检索能力(MIRACL)
在多语言评测上,BGE-M3稠密向量(Dense)检索能力在每种语言上都实现了有竞争力的效果,整体水平显著优于此前的基线向量模型(如mE5)。稀疏检索(Sparse)大幅超过了传统的稀疏匹配算法BM25。多向量检索(multi-vector)则获得了三种检索方式中的最佳效果。与此同时,BGE-M3通过搭配多种检索方式以进一步提升检索质量。如下表所示,稠密与稀疏搭配的方法(Dense+Sparse)超过了使用单一手段的检索效果,联合使用三种检索方法(All: Dense+Sparse+Multi-cector)则可以获得最优的结果。
https://project-miracl.github.io2. 跨语言检索能力(MKQA)
BGE-M3在跨语言任务上依然具备最佳的检索效果。得益于训练阶段更加广泛的语言覆盖,BGE-M3不仅总体水平显著超越基线模型,同时在各个任务上都保持了很强的竞争力。与此前实验结果相类似,BGE-M3同样可以通过搭配多种检索方式进一步提升跨语言检索的效果。但值得注意的是,稀疏检索并不擅长应对跨语言检索这种词汇重合度很小的场景。因此,稀疏检索的自身效果以及与其他方法混搭所带来的收益相对较小。跨语言检索任务评测(MKQA)
https://github.com/apple/ml-mkqa
3. 长文档检索能力 (MLRB: Multi-Lingual Long Retrieval Benchmark)
BGE-M3可以支持长达8192的输入文档,同时长文档检索的效果要显著优于此前的基线模型。非常有意思的是,从实验结果可以观察到,稀疏检索(Sparse)的效果要显著高于稠密检索(Dense),这说明关键词信息对于长文档检索极为重要。 https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3
为了探究长文档检索能力的来源,智源研究员进一步剥离了长文档检索的微调数据(w.o.long)。实验结果显示,BGE-M3通过预训练阶段的学习就已经获得了非常出色的长文档检索能力,单纯使用稠密检索(Dense-w.o.long)就可以实现与E5-mistral相当的实验效果。考虑到 E5-mistrial 使用了高于 BGE-M3 数十倍的参数以及高达4096的向量维度,BGE-M3 在实际中使用成本将远低于 E5-mistrial,是颇具竞争力的。此外,研究人员还尝试在长文档中插入多个 CLS token以强化长文档建模效果(MCLS:Multiple CLS,详见技术报告)。实验发现,将这一策略不加训练而直接应用在推理时(Dense-w.o.long MCLS)就可以得到非常明显的效果增益。BGE-M3技术路线简介

如BGE模型一致,BGE-M3模型训练分为三个阶段:1)RetroMAE预训练,在105种语言的网页数据和wiki数据上进行,提供一个可以支持8192长度和面向表示任务的基座模型;2)无监督对比学习,在194种单语言和1390种翻译对数据共1.1B的文本对上进行的大规模对比学习;3)多检索方式统一优化,在高质量多样化的数据上进行多功能检索优化,使模型具备多种检索能力。其中,一些重要的关键技术如下:1. 自学习蒸馏
人类可以利用多种不同的方式计算结果,矫正误差。模型也可以,通过联合多种检索方式的输出,可以取得比单检索模式更好的效果。因此,BGE-M3使用了一种自激励蒸馏方法来提高检索性能。具体来说,合并三种检索模式的输出,得到新的文本相似度分数,将其作为激励信号,让各单模式学习该信号,以提高单检索模式的效果。2. 训练效率优化
由于引入了大量文本长度差异极大的训练数据,常规的对比学习训练方法的效率非常低下。一方面,长文本会消耗相当多的显存,大大的限制了训练时的batch size。其次,短文本不得不填充至更长的长度以对齐同一批次的长文本,这样就引入了大量无意义的计算。此外,训练数据的长度差异容易使得不同GPU之间的计算负荷分布不均并引发相互等待,造成不必要的训练延时。为了解决这些问题,我们优化了训练流程。该过程如图所示。
3. 长文本优化
目前,开源社区缺少用于文档级检索的开源数据集。为此,我们借助大语言模型生产了一份包括13种语言的长文档检索数据。另外,由于缺乏长文本数据或计算资源,实际情况下长文本微调不一定可以进行。在这种情况下,我们提出了一种简单而有效的方法:MCLS(Multiple CLS)来增强模型的能力,而无需对长文本进行微调。如下图所示,MCLS方法旨在利用多个CLS令牌来联合捕获长文本的语义。具体来说,我们为每个固定数量的令牌插入一个cls令牌,每个cls令牌可以从相邻的令牌获取语义信息。最后,通过对所有cls令牌的最后隐藏状态求平均值来获得最终的文本嵌入。
开发者使用示例
不同检索方式的介绍:
在BGE-M3模型中,输入一个文本对,可同时得到三种模式的分数,三种模式同时又可相互组合得到新的总分。
如何使用模型生成多种模式下的向量,具体参考 FlagEmbedding开源仓库示例。对于RAG中检索器的建议:推荐使用混合检索+重新排序,足以应对大多数情况。
[1] BGE. https://github.com/FlagOpen/FlagEmbedding[2] C-Pack. C-Pack: Packaged Resources To Advance General Chinese Embedding[3] RetroMAE. RetroMAE: Pre-Training Retrieval-oriented Language Models Via Masked Auto-Encoder[4] mE5. https://huggingface.co/intfloat/multilingual-e5-large[5] OpenAI Text Embedding. https://openai.com/blog/new-embedding-models-and-api-updates[6] ColBERT. ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT
FlagEmbedding 是「智源FlagOpen大模型开源技术体系」的重要组成部分。FlagOpen 旨在打造全面支撑大模型技术发展的开源算法体系和一站式基础软件平台,支持协同创新和开放竞争,共建共享大模型时代的“Linux”开源开放生态。更多开源项目见官方网站:
https://flagopen.baai.ac.cn