就算是 OpenAI 在舆论场也无法逃过版权保护的呼声。
GPT-4o内置声音模仿「寡姐」一案闹的沸沸扬扬,虽然以OpenAI发布声明暂停使用疑似寡姐声音的「SKY」的语音、否认曾侵权声音为阶段性结束。但是,一时间「即便是AI,也得保护人类版权」这一话题甚嚣尘上,更刺激起了人们本来就对AI是否可控这一现代迷思的焦虑。近日,普林斯顿大学、哥伦比亚大学、哈佛大学和宾夕法尼亚大学共同推出了一项关于生成式AI版权保护的新方案,题为《An Economic Solution to Copyright Challenges of Generative AI》。- 论文链接:https://arxiv.org/abs/2404.13964
生成式人工智能(AI)技术的快速进展已经深刻影响了文艺产业,带来了文学、视觉艺术和音乐等领域中由AI生成的内容时代。这些AI模型如大型语言模型和扩散模型能够创作出能够与人类艺术家的作品媲美乃至可能取代的高复杂性内容。这种能力的迅速增长引发了关于大模型训练数据作者权利的法律和道德界限的重要问题,特别是在版权侵犯方面的争议。版权保护一直以来都是各国法律中不可或缺的一部分。保护创作者的权益,可以更有利于调动创作者的积极性,使得文化事业更加繁华。版权保护为创作者不止提供了精神支持,也同时提供了物质支持 (利益分配),这也是为创作者进一步提供了再创作的物质基础和精神动力。另一方面,版权保护也更利于优秀作品的传播,因为版权保护也是在保护传播者的正当权益和保护公众对于分享知识文化成果的权利。诚然,一部作品的诞生,不是为了孤芳自赏,更多的是为了以某种形式分享给大众,为大众所用。而且, 版权保护也可以让创作者更加合理地使用他人的结果,避免引发剽窃等诸多麻烦。因此,目前有几家AI公司因涉嫌生产侵犯版权的内容而卷入法律诉讼。比如说 《纽约时报》起诉 Chatgpt的开发者 OpenAI [1],控诉后者将数百万篇 《纽约时报》的文章被用于训练智能聊天机器人(例如ChatGPT )。这些机器人现在作为新闻消息源与《纽约时报》展开竞争。《纽约时报》声称,OpenAI和微软大型语言模型 (LLM)能够模仿《纽约时报》的文字风格从而生成类似内容,有时候甚至能原封不动生成已有的内容,这种现象影响到《纽约时报》通过订阅和广告获得收入,并且有违版权许可。起诉书中,《纽约时报》提及到一个例子 – 微软的「以必应浏览(Browse With Bing)」中的功能,能够几乎一字不差地重现《纽约时报》旗下网站「The Wirecutter」的内容,但完全没有为提供相关的链接进行引用。这个例子充分体现了AI 非法使用版权内容。目前,针对OpenAI的类似诉讼案件正在不断增加,例如近来GPT-4o内置声音模仿「寡姐」一案 [2]。但由于对于AI 非常使用版权内容难以界定,诉讼案件尚在激烈讨论中。图1:NY Times指控ChatGPT生成内容和NY Times文章高度一致。为了缓解训练数据版权所有者与AI开发者之间的紧张关系,人们已经开始尝试修改生成模型的训练或推理过程,以减少生成侵权内容的可能性。然而这些改动可能会因为排除了高质量的受版权保护的训练数据或限制内容生成而损害模型性能。版权法的复杂性和模糊性增加了额外的难度,使得区分侵权和非侵权成果变得模糊不清。这种不确定性可能导致双方在法庭争议中浪费大量资源。本文提出一种在AI开发者和版权所有者之间建立互利的收益分享协议的方案,此提议呼应了经济学中最近提倡的观点。然而,模型训练和内容生成的「黑箱」特性使得传统的按比例直接分成方法不再适用。因此,需要一种新的框架来公平合理地处理这些新出现的版权问题,确保在鼓励创新的同时,也保护数据提供者的合法权益。- 第一步是评估模型在整个数据集的每一个可能子集上训练的效用。直观上,如果在某数据子集上训练的模型能够有很大的可能性生成与部署模型相似的AI生成内容(例如艺术作品),那么该数据子集的效用就会很大。
- 第二步是根据第一步的效用使用合作博弈论工具(即Shapley值)来确定任何训练数据版权所有者的应得份额。简而言之,如果将其数据包括在模型训练中能够增加效用,那么版权所有者的份额就会大。
设有 n 个版权所有者,第 i个拥有训练数据集 的版权,其中i∈N≔{1,2,…n}。部署的模型训练在整个数据集
的版权,其中i∈N≔{1,2,…n}。部署的模型训练在整个数据集 上,并生成内容
上,并生成内容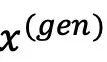 。考虑一个在数据子集
。考虑一个在数据子集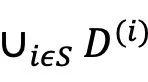 上训练的反事实模型,其中S⊆N表示数据所有者的一个子集。该反事实模型生成同一内容
上训练的反事实模型,其中S⊆N表示数据所有者的一个子集。该反事实模型生成同一内容 的概率密度函数由
的概率密度函数由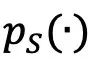 表示。对于生成模型生成的内容,一个子集的效用最容易反映在该反事实模型生成目标内容的概率。当比较不同模型时,可以通过生成目标内容的概率比例衡量它们之间的效用差距。因此,该文章定义此模型对内容的
表示。对于生成模型生成的内容,一个子集的效用最容易反映在该反事实模型生成目标内容的概率。当比较不同模型时,可以通过生成目标内容的概率比例衡量它们之间的效用差距。因此,该文章定义此模型对内容的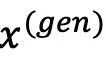 效用为
效用为 ,这样可以直接根据
,这样可以直接根据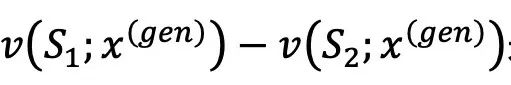 来比较两个数据集之间的效用。这种效用提供了一种衡量数据源S在生成内容方面的责任程度的方式。如果反事实模型不太可能生成与部署模型相同的内容,其效用就小,反之亦然。效用v(S)可以解释为所有S成员为训练生成式AI模型提供数据所应得的总补偿。下一步是基于所有可能的数据源组合的效用来确定每个个别版权所有者的收益。该文章提议使用Shapley值。Shapley值是博弈论中的一个解决方案概念,它提供了一种根据每个玩家组合作为联盟的效用分配收益的原则性方法。它是由诺贝尔奖获得者Lloyd Shapley (此后简称为Shapley) 提出的。Shapley (1923-2016)是美国籍数学家和经济学家,并且由于对稳定分配理论和市场设计的实践做出突出贡献,而获得了2012年的经济学诺贝尔奖 [3]。Shapley是博弈论领域的传奇,并且在其博士工作和博士论文中引入了Shapley值。美国经济学会称Shapley是「博弈论和经济学理论的巨人」。参与者i的Shapley值计算为其在所有可能联盟中边际贡献的加权平均:Shapley值是唯一满足几个重要经济属性的支付规则,并在机器学习模型的数据估值中获得了普及。利用Shapley值,该文章提出使用SRS(Shapley Royalty Share)来计算版权分配。这里,
来比较两个数据集之间的效用。这种效用提供了一种衡量数据源S在生成内容方面的责任程度的方式。如果反事实模型不太可能生成与部署模型相同的内容,其效用就小,反之亦然。效用v(S)可以解释为所有S成员为训练生成式AI模型提供数据所应得的总补偿。下一步是基于所有可能的数据源组合的效用来确定每个个别版权所有者的收益。该文章提议使用Shapley值。Shapley值是博弈论中的一个解决方案概念,它提供了一种根据每个玩家组合作为联盟的效用分配收益的原则性方法。它是由诺贝尔奖获得者Lloyd Shapley (此后简称为Shapley) 提出的。Shapley (1923-2016)是美国籍数学家和经济学家,并且由于对稳定分配理论和市场设计的实践做出突出贡献,而获得了2012年的经济学诺贝尔奖 [3]。Shapley是博弈论领域的传奇,并且在其博士工作和博士论文中引入了Shapley值。美国经济学会称Shapley是「博弈论和经济学理论的巨人」。参与者i的Shapley值计算为其在所有可能联盟中边际贡献的加权平均:Shapley值是唯一满足几个重要经济属性的支付规则,并在机器学习模型的数据估值中获得了普及。利用Shapley值,该文章提出使用SRS(Shapley Royalty Share)来计算版权分配。这里,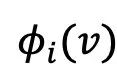 是版权所有者i的Shapley值。SRS提供了一种经济学方法解决生成式AI环境中的版权和收益分配问题,支持公正的数据使用和创新激励。该文章用一个简单的例子来解释Shapley值的计算过程。在这个例子中,有三个数据所有者(A, B, C),他们共同训练一个模型,使用模型对某生成内容的log-likelihood作为效用函数。假设使用不同的数据组合训练后的模型的log-likelihood如下:
是版权所有者i的Shapley值。SRS提供了一种经济学方法解决生成式AI环境中的版权和收益分配问题,支持公正的数据使用和创新激励。该文章用一个简单的例子来解释Shapley值的计算过程。在这个例子中,有三个数据所有者(A, B, C),他们共同训练一个模型,使用模型对某生成内容的log-likelihood作为效用函数。假设使用不同的数据组合训练后的模型的log-likelihood如下:- 数据所有者A和B的贡献:v({A,B})-v({B})=15-7=8
- 数据所有者A和C的贡献:v({A,C})-v({C})=10-3=7
- 数据所有者A、B和C的贡献:v({A,B,C})-v({B,C})=20-12=8
在应用SRS框架时,主要挑战在于其相当大的计算成本。对不同数据源组合的效用函数评估需要多次重新训练模型。在版权所有者数量较少的某些应用中,计算挑战可能并不像看起来那么严重。实际上,可以预见这种基于合约的框架在整个版权数据被少数几个版权所有者分割时效果最佳,这样每个数据源都有足够的数据影响训练结果。如果数据源的规模非常小,版权所有者的版税份额可能微不足道,且由于训练AI模型的随机性,结果可能更加噪声化。- 第一种是使用蒙特卡洛方法来近似计算Shapley值,这种技术特别适用于版权所有者众多的情况。
- 第二种方法是通过从另一个在较小数据子集上训练的模型微调来训练模型。因此,可以通过对整个训练数据只训练一次,来近似在不同数据子集上训练的模型。具体来说,对于随机抽样的版权所有者排列,可以首先在第一个版权所有者上训练,然后是第二个,一直到最后一个版权所有者。这种技术可以与著名的Shapley值排列抽样估计器一起使用。
在实践中,商业AI模型可能每天进行数百万次交易。仅估计每个版权所有者应得的聚合收益,而不是按照公式为每个AI生成的内容计算收益,可以节省计算成本。理论上,可以仅评估所有交易中一小部分的SRS,然后按比例计算从所有交易中获得的收入分布。该文章通过实验评估了所提出框架在分配AI生成内容版税方面的有效性,重点关注创意艺术和图像领域的标志设计。评估使用了公开可获取的数据集:WikiArt和FlickrLogo-27。对于WikiArt数据集,该文章选取了四位著名艺术家的四个不相交的画作子集。一个最初在更广泛的训练图像集(不包括这四位艺术家的作品)上训练的模型,作为基础模型。通过在选定艺术家的四组画作的各种组合上进一步微调基础模型,计算SRS。类似地,对于FlickrLogo-27数据集,该文章选取了四个品牌的四个不相交的标志设计子集,并使用在其他品牌标志图像上训练的基础模型计算SRS。该文章的目标是评估SRS是否能反映每个版权所有者对图像生成的贡献。图4:使用SRS评估每个版权所有者对图像生成的贡献。结果表明,当 的风格与训练数据源的风格非常接近时,SRS值最高。这一关系凸显了SRS框架准确归因于AI生成图像创作贡献的能力。在WikiArt数据集上,该文章探讨了针对要求从多个数据源生成内容的提示的SRS分布。显著地,提示要求生成模型融合多位艺术家的风格。SRS有效地识别并奖励了融入生成艺术作品的数据源的贡献,展示了该框架在辨识和评价多样化数据源输入以生成内容的能力。图5:使用SRS评估每个版权所有者对混有不同艺术家风格的图像生成的贡献。生成式AI的快速发展对传统版权法构成了深刻挑战,这不仅是因为其强大的内容生成能力,还因为对AI生成内容版权的解释复杂以及大型AI系统的“黑箱”本质。该文章从经济学角度出发,开发了一个允许在版权数据训练中交换收入分配的版权分享模型,促进了AI开发者和版权所有者之间的互利合作。通过数值实验,该文章证明了这一框架的有效性和可行性。该文章的研究也为未来的研究开辟了道路。例如,版权所有者可能会通过合并或分割他们的数据来最大化版权分成,SRS可能会被恶意版权所有者操纵。尽管已经探索了抗复制的解决方案,但这些主要关注于Shapley值的影响而非复制下的比率。开发一种抗操纵的机制是未来工作的一个重要方向。另一个开放问题是处理无法或不愿意协商协议的版权所有者的版权数据,特别是当每个拥有者的数据集很小的情况。在这种情况下,该文章的方法可以与生成合法内容的方法结合使用, 增强他们的模型以确定版权所有者和AI开发者之间适当的收入分配,认识到计算资源、算法设计和工程专长在开发高性能AI模型中的关键作用,是另一个研究方向。该文章已经通过采用合作博弈理论中的权限结构概念来初步适应这种情况。从方法论角度看,未来研究的一个关键方面是使用Shapley值比率进行收入分配。直接使用Shapley值的主要挑战在于任何版权所有者数据联盟的总收入未知。但当考虑比率时,Shapley值的效率属性(确保所有Shapley值之和等于大联盟的效用)失去了意义。在这种情况下,半值(一种放弃效率公理的Shapley值推广)可能提供了一个可行的替代方案。未来的工作可以旨在建立公理化的理由,以识别此背景下用于版税分配的最合适的解决方案概念。从实用性的角度讲,Shapley值最大的不足之处在于计算开销。尽管Monte Carlo方法可以加速计算过程,但仍需要大量的模型重复训练。这种计算需求在处理大型数据集和复杂模型时变得尤其突出,可能导致计算资源的极大消耗和时间的延长。未来的工作可以着重于解决这一问题,通过开发更高效的算法或启用新的方法来减少计算开销,从而使Shapley值在实际应用中更加可行和高效。
的风格与训练数据源的风格非常接近时,SRS值最高。这一关系凸显了SRS框架准确归因于AI生成图像创作贡献的能力。在WikiArt数据集上,该文章探讨了针对要求从多个数据源生成内容的提示的SRS分布。显著地,提示要求生成模型融合多位艺术家的风格。SRS有效地识别并奖励了融入生成艺术作品的数据源的贡献,展示了该框架在辨识和评价多样化数据源输入以生成内容的能力。图5:使用SRS评估每个版权所有者对混有不同艺术家风格的图像生成的贡献。生成式AI的快速发展对传统版权法构成了深刻挑战,这不仅是因为其强大的内容生成能力,还因为对AI生成内容版权的解释复杂以及大型AI系统的“黑箱”本质。该文章从经济学角度出发,开发了一个允许在版权数据训练中交换收入分配的版权分享模型,促进了AI开发者和版权所有者之间的互利合作。通过数值实验,该文章证明了这一框架的有效性和可行性。该文章的研究也为未来的研究开辟了道路。例如,版权所有者可能会通过合并或分割他们的数据来最大化版权分成,SRS可能会被恶意版权所有者操纵。尽管已经探索了抗复制的解决方案,但这些主要关注于Shapley值的影响而非复制下的比率。开发一种抗操纵的机制是未来工作的一个重要方向。另一个开放问题是处理无法或不愿意协商协议的版权所有者的版权数据,特别是当每个拥有者的数据集很小的情况。在这种情况下,该文章的方法可以与生成合法内容的方法结合使用, 增强他们的模型以确定版权所有者和AI开发者之间适当的收入分配,认识到计算资源、算法设计和工程专长在开发高性能AI模型中的关键作用,是另一个研究方向。该文章已经通过采用合作博弈理论中的权限结构概念来初步适应这种情况。从方法论角度看,未来研究的一个关键方面是使用Shapley值比率进行收入分配。直接使用Shapley值的主要挑战在于任何版权所有者数据联盟的总收入未知。但当考虑比率时,Shapley值的效率属性(确保所有Shapley值之和等于大联盟的效用)失去了意义。在这种情况下,半值(一种放弃效率公理的Shapley值推广)可能提供了一个可行的替代方案。未来的工作可以旨在建立公理化的理由,以识别此背景下用于版税分配的最合适的解决方案概念。从实用性的角度讲,Shapley值最大的不足之处在于计算开销。尽管Monte Carlo方法可以加速计算过程,但仍需要大量的模型重复训练。这种计算需求在处理大型数据集和复杂模型时变得尤其突出,可能导致计算资源的极大消耗和时间的延长。未来的工作可以着重于解决这一问题,通过开发更高效的算法或启用新的方法来减少计算开销,从而使Shapley值在实际应用中更加可行和高效。1. Jiachen Wang (王嘉宸):现为普林斯顿大学电子工程系博士生,主攻人工智能数据估值(data valuation)等方向。
2. Zhun Deng (邓准):现为哥伦比亚大学计算机系博后,博后导师为 Richard Zemel。此前为哈佛大学计算机系博士生,师从Cynthia Dwork,主攻机器学习可靠性和社会责任性等方向。
3. Hiroaki Chiba-Okabe:现为宾夕法尼亚大学应用数学和计算科学博士生,主攻方向是人工智能引发的道德问题和社会问题。
4. Boaz Barak: 哈佛大学正教授,主攻方向理论计算机和机器学习方向。同时在OpenAI 任职。
5. Weijie Su (苏炜杰):现为宾夕法尼亚大学沃顿商学院、计算机系和数学系副教授,研究方向包括人工智能的理论基础等方向。
[1]https://www.nytimes.com/2023/12/27/business/media/new-york-times-open-ai-microsoft-lawsuit.html [2] https://world.huanqiu.com/article/4HuwDTOteIL [3] https://en.wikipedia.org/wiki/Shapley_value
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]