本文在回顾分布式深度强化学习 DDRL 基本框架的基础上,重点介绍了 IMPALA 框架系列方法。
AlphaGo 是一个在人机博弈中赢得众多职业围棋手的 agent 机器人。随着 AlphaGo 的突破,深度强化学习(Deep Reinforcement Learning,DRL)成为一种公认的解决连续决策问题的有效技术。人们开发了大量算法来解决介于 DRL 与现实世界应用之间的挑战性问题,如探索与开发困境、数据低效、多 agent 合作与竞争等。在所有这些挑战中,由于 DRL 的试错学习机制需要大量交互数据,数据低效(data inefficiency)是最受诟病的问题。为了应对这一问题,受到分布式机器学习技术的启发,分布式深度强化学习 (distributed deep reinforcement learning,DDRL) 已提出并成功应用于计算机视觉和自然语言处理领域。有观点认为,分布式强化学习是深度强化学习走向大规模应用、解决复杂决策空间和长期规划问题的必经之路。一般来说,DRL agent 的训练包括两个主要部分:通过策略网络参数驱动环境交互以生成数据,以及通过消耗数据更新策略网络参数。这种结构化模式使得对 DRL 进行分布式化处理变得可行,并陆续研发出了大量 Distributed DRL (DDRL) 算法。此外,为了使 DDRL 算法能够利用多台机器,还需要解决几个工程问题,如机器通信和分布式存储,以及在保证算法优化收敛性的同时,尽可能地提升其中各个环节的效率。分布式强化学习是一个综合的研究子领域,需要深度强化学习算法以及分布式系统设计的互相感知和协同。考虑到 DDRL 的巨大进步,我们有必要梳理 DDRL 技术的发展历程、挑战和机遇,从而为今后的研究提供线索。近年来,分布式强化学习快速发展,关于分布式强化学习的架构、算法、关键技术等的研究论文众多。我们将分为两个 part 分别介绍 DDRL 的前世(经典方法)和今生(最新进展)。本文为 part 1,在回顾 DDRL 基本框架的基础上,重点介绍 IMPALA 框架系列方法,主要思路是:使用异步架构,在提升样本吞吐量的同时,引入一些 off-policy 修正。目前已开发出大量 DDRL 算法或框架,其中具有代表性的有 GORILA、A3C、APEX、IMPALA、Distributed PPO、R2D2 、 Seed RL 等,在此基础上,我们梳理总结得出 DDRL 基本框架,如图 1 所示 [1]。
在 DDRL 研究中,通常使用框架代替算法或方法的表述,是因为这些框架并不针对特定的强化学习算法,它们更像是各种强化学习方法的分布式框架。一般来说,基本的 DDRL 主要有三个部分,它们构成了 single player single agent DDRL 方法:- 行动者(Actors):通过与环境互动产生数据(轨迹或梯度)。
- 学习者(Learners):消耗数据(轨迹或梯度),执行神经网络参数更新。
- 协调者(Coordinator):协调数据(参数或轨迹),控制 learner 和 actor 之间的通信。
具体来说,协调者(Coordinator)用于和环境交互产生数据的协调,其中包含环境本身(Env)和产生动作的行动者(Actors),以及使用这些数据进行训练的学习者(Learners),他们各自需要不同数量和类型的计算资源支持。而根据算法和环境类型的不同,又会有一些延伸的辅助模块,例如大部分 off-policy 算法都会需要数据队列(Replay Buffer)来存储训练数据,对于 model-based RL 相关的算法又会有学习环境 dynamics 的相关训练模块,而对于需要大量自我博弈(self-play)的算法,还需要一个中心化的 Coordinator 去控制协调各个组件(例如动态指定自己博弈的双方)。协调者可以控制 learner 和 actor 之间的通信。例如,当协调者用于同步参数更新和拉取(由 actor 进行)时,DDRL 算法就是同步的。当参数更新和拉取(actor)没有严格协调时,DDRL 算法就是异步的。因此,可以根据协调者类型对 DDRL 算法进行基本分类。- 同步:全局策略参数的更新是同步的,策略参数的调用(由 actor 调用)也是同步的,即不同的 actor 共享相同的最新全局策略。
- 异步:全局策略参数的更新是异步的,或者说策略更新(由 learner 进行)和拉动(由 actor 进行)是异步的,即 actor 和 learner 通常拥有不同的策略参数。
利用图 1 中给出的基本框架,可以设计出 single player single agent 的 DDRL 算法(文献 [1] 中定义 player,即为分布式架构中的 agent,本文中以 agent 指代)。但是,当面对多个 agent 时,基本框架无法训练出可用的 RL agent。基于目前支持大型系统级人工智能的 DDRL 算法,如 AlphaStar、OpenAI Five 和 JueWU,要构建多 agent DDRL,有两个关键要素必不可少,即 agent 合作和进化,如图 2 所示。
图 2. single player(agent) single agent DDRL 到 multiple players(agents) multipleagents DDRL基于多 agent 强化学习算法,agent 合作模块用于训练多个 agents。一般来说,多 agent 强化学习可以根据 agent 关系建模的方式分为独立训练和联合训练两类。- 独立训练:将其他学习 agent 视为环境的一部分,对每个 agent 进行独立训练。
- 联合训练:将所有 agent 作为一个整体进行训练,同时考虑 agent 交流、奖励分配、集中训练与分布式执行等因素。
进化模块是为每个 agent 迭代而设计的,其他 agent 在同一时间学习,导致每个 agent 需要学习不止一代 agent,如 AlphaStar 和 OpenAI Five。根据目前主流的进化技术,进化可分为两种类型:- Self-play based:不同 agent 共享相同的策略网络,agent 通过与自己过去的版本对抗来更新当前一代的策略。
- Population-play based:不同的 agent 拥有不同的策略网络,或称为 population,agent 通过与其他 agent 或 / 和其过去的版本对抗来更新其当前一代的策略。
最后,根据上述 DDRL 的关键要素,DDRL 的分类法如图 3 所示。
我们在这一章节中,重点回顾经典的分布式强化学习方法。这些方法多为前几年提出的,其性能与最新方法仍有差距,我们在 part1 中回顾这些经典方法,以了解分布式强化学习发展初期,重点在哪些方面对传统的强化学习以及分布式架构进行了改进。2.1 Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architecture [2]
IMPALA(Importance Weighted Actor-Learner Architecture)是 DeepMind 推出的一种异步分布式深度强化学习架构,目的是让一个 Agent(single agent)学会多种技能(https://github.com/deepmind/lab/tree/master/game_scripts/levels/contributed/dmlab30)。相关内容发表在 ICML 2018 中。ICML 2018 是第 35 届国际机器学习会议,在斯德哥尔摩举办。ICML 2018 共有 2473 篇有效投稿,其中 618 篇被接收,接收率为 25.1%。IMPALA 尝试利用单 agent 同时处理多个任务,其架构性能超越此前方法数倍,具有强大的可扩展性,同时也展示了积极的迁移性质。IMPALA 是典型的异步架构。与 IMPALA 架构同时提出的还有任务集合 DMLab-30。
图 4. 左图:singer learner。每个 actor 生成轨迹并通过队列发送给 learner。在开始下一个轨迹之前,actor 会从 learner 那里获取最新的策略参数;右图:多个同步 learner。策略参数分布在多个同步工作的 learner 中如图 4,在 IMPALA 架构中,每个 Actor 都拥有一个模型副本,Actor 发送训练样本给 Learner,Learner 更新模型之后,会将新模型发送给 Actor。在整个过程中,Actor 和 Learner 一直在异步运行中,即 Learner 只要收到训练数据就会更新模型,不会等待所有的 Actor;而 Actor 在 Learner 更新模型时依然在采样,不会等待最新的模型。显然,这样的运行方式会产生 off-policy 现象,即行为策略和目标策略不一致。在 IMPALA 中,作者在数学上推导出了一种严谨的修正方式:V-trace 算法。该算法显著降低了训练样本 off-policy 带来的影响。行为策略(Behavior Policy)就是智能体用来和环境交互产生样本的策略;目标策略(Target Policy)就是根据行为策略产生的样本来不断学习和优化的策略,即训练完成最终用来使用的策略。
IMPALA 使用 actor critic 设置来学习策略 π 和基线函数 V^π。生成经验的过程与学习 π 和 V^π 的参数是分离的。该架构由一组重复生成经验轨迹(trajectory)的 actor 和一个或多个 learner 组成,learner 利用 actor 发送的经验来学习 off policy π。在每条轨迹开始时,actor 会将自己的本地策略 µ 更新为最新的 learner 策略 π,并在其环境中运行 n 步。n 步之后,actor 将状态、行动和奖励的轨迹 x_1、a_1、r_1、...... 、 x_n、a_n、r_n 以及相应的策略分布 µ(a_t|x_t) 和初始 LSTM 状态通过队列发送给 learner(典型 DRL agent 架构由卷积网络、LSTM、全连接层组成)。然后,learner 会根据从许多 actor 那里收集到的轨迹批次不断更新其策略 π。通过这种简单的架构,learner 可以使用 GPU 加速,actor 也可以轻松地分布在多台机器上。然而,在更新时,learner 的策略 π 有可能比 actor 的策略 µ 超前数次,因此 actor 和 learner 之间存在策略滞后。V-trace 可纠正这种滞后现象,在保持数据效率的同时实现极高的数据吞吐量。使用强化学习中经典的 actor-learner 架构,可提供与分布式 A3C 类似的容错能力,但由于 actor 发送的是观测数据而非参数 / 梯度,因此通常通信开销较低。随着深度模型架构的引入,单个 GPU 的速度往往成为训练过程中的限制因素。IMPALA 可以与分布式 learner 集一起使用,高效地训练大型神经网络。参数分布在 learner 中,actor 从所有 learner 中并行检索参数,同时只向单个 learner 发送观察结果。IMPALA 使用同步参数更新,这对于在扩展到多台机器时保持数据效率至关重要。GPU 和多核 CPU 从运行少量大型可并行运算而非大量小型运算中获益匪浅。由于 IMPALA 中的 learner 对整批轨迹执行更新,因此与 A3C 这样的 online agent 相比,它能够并行化更多的计算。举例来说,典型的 DRL agent 有一个卷积网络,然后是一个 LSTM,在 LSTM 之后是一个全连接输出层。IMPALA learner 通过将时间维度折叠到批次维度,将卷积网络并行应用于所有输入。同样,一旦计算出所有 LSTM 状态,它还会并行将输出层应用到所有时间步骤。这一优化将有效批次规模增加到数千次。通过利用网络结构依赖性和操作融合,基于 LSTM 的 agent 还能显著提高 learner 的速度。最后,还利用了 TensorFlow 中几种现成的优化方法,例如在进行计算的同时为 learner 准备下一批数据,使用 XLA(TensorFlow 即时编译器)编译计算图的部分内容,以及优化数据格式以获得 cuDNN 框架的最高性能等。在解耦分布式 actor-learner 架构中,off policy 学习非常重要,因为 actor 生成行动与 learner 估计梯度之间存在滞后。为此,本文为 learner 引入了一种名为 V-trace 的 off policy actor-critic 方法。首先,我们先介绍一些术语。我们考虑的是马尔可夫决策过程(Markov Decision Processes,MDP)中的 discounted infinite-horizon RL 问题,其目标是找到一个能使未来 discount reward 的预期总和最大化的策略 π:
其中,γ 为 discount factor。r_t = r (x_t, a_t) 是时间 t 的奖励,x_t 是时间 t 的状态(初始化为 x_0 = x),a_t ∼ π(・|x_t) 是遵循策略 π 所产生的行动。Off policy RL 算法的目标是利用某种策略 µ(称为行为策略)生成的轨迹来学习另一种策略 π(可能与 µ 不同)(称为目标策略)的值函数 V^π。考虑 actor 按照某种策略 µ 生成的轨迹。我们将 V (x_s) 的 n-steps V-trace 目标定义为: (1)
(1)
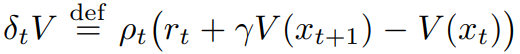


其中,δ_t V 表示 V 的时间差,ρ_t 和 c_i 为截断重要度抽样 (IS) 权重。在 on-policy 的情况下(当 π = µ 时),假设 c¯≥ 1,则所有 c_i = 1,ρ_t = 1,此时式 (1) 改写为:
即 on-policy n-steps Bellman 目标。因此,在 on-policy 情况下,V-trace 简化为 on-policy n-steps Bellman 更新。这一特性(Retrace 并不具备)允许我们在 off-policy 数据和 on-policy 数据中使用相同的算法。截断的 IS 权重 c_i 和 ρ_t 起着不同的作用。权重 ρ_t 出现在 δ_t V 的定义中,并定义了该更新规则的 fixed point。在函数可以完美表示的情况下,这种更新的 fixed point(即所有状态下 V (x_s) = v_s)(δt V 的期望值等于零(在 µ 条件下))是某种策略 πρ¯ 的值函数 V^(π_ρ¯),其定义为:
因此,当 ρ¯ 是无穷大时(即 ρ_t 没有截断),这就是目标策略的价值函数 V^π。然而,如果我们选择一个截断水平 ρ¯<∞,我们的 fix point 就是介于 µ 和 π 之间的策略 πρ¯ 的价值函数 V^(πρ¯)。在 ρ¯ 接近零的极限情况下,我们得到行为策略的价值函数 V^µ。π 和 µ 越不相似(越偏离策略),这个乘积的方差就越大。作者使用截断水平 c¯ 作为减少方差的技术。我们可以看到,截断水平 c¯ 和 ρ¯ 代表了算法的不同特征:ρ¯ 影响收敛到的价值函数的性质,而 c¯ 则影响收敛到该函数的速度。
备注 2. 与 Retrace (λ) 一样,我们也可以在 V-trace 的定义中考虑额外的 discounting 参数 λ∈ [0, 1],方法是设置:
在 on policy 情况下,当 n = ∞ 时,V-trace 简化为 TD (λ)。在 on policy 的情况下,价值函数 V^µ(x_0) 相对于策略参数 µ 的梯度为:

Q^µ(x_s, a_s) 表征策略 µ 在 (x_s, a_s) 位置的 state-action 值。这通常通过随机梯度上升来实现,该梯度上升在如下方向上更新策略参数: (4)
(4)
其中,q_s 是 Q^µ(x_s, a_s) 的估计值,并在某些行为策略下访问的状态 x_s 的集合上求平均值。现在,在我们考虑的 off-policy 设置中,可以使用正在评估的策略 π_ρ¯ 和行为策略 µ 之间的 IS 权重,以更新方向中的策略参数:
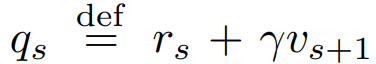
其中,q_s 根据下一状态 x_s+1 下的 V-trace 估计 v_s+1 构建。作者使用 q_s 而不是 v_s 作为 Q value 目标的原因是,假设我们的值估计在所有状态下都是正确的,即 V=V^(π_ρ¯),那么我们有:
为了减少策略梯度估计式 (4) 的方差,通常从 q_s 中减去状态相关的基线,例如当前值近似 V (x_s)。最后注意,式 (4) 估计 π_ρ¯ 的策略梯度,π_ρ¯ 是在使用截断级别时由 V-trace 算法评估的策略。然而,假设偏差 V^(π_ρ¯)=V^π 很小(如果 ρ¯ 足够大),那么我们可以期望 q_s 为我们提供 Q^π(x_s, a_s) 的良好估计。由此,作者推导出以下规范的 V-trace actor-critic 算法:V-TRACE ACTOR-CRITIC ALGORITHM考虑价值函数的参数表示 V_θ 和当前策略 π_ω。actor 遵循某些行为策略而生成轨迹 μ。v_s 由式 (1) 定义。在训练时间 s,通过对目标 v_s 的 2 次损失的梯度下降来更新值参数 θ,即在如下方向:

为了防止过早收敛,可以像在 A3C 中一样,沿着方向添加 entropy bonus:
整体更新是通过将这三个梯度相加来获得的,其中,三个梯度由适当的系数重新缩放。作者实验验证了 IMPALA 在多种设置下的性能。在数据效率、计算性能和 off-policy 校正的有效性方面,具体研究了在单个任务上训练的 IMPALA agent 的学习行为。在多任务学习方面,在新引入的 30 个 DeepMind 实验室任务集和 the Atari 学习环境的全部 57 个游戏上训练 agent— 每个 agent 在所有任务中都使用一组权重。在所有实验中,使用了两种不同的模型架构:一种是在策略和价值之前使用 LSTM 的浅层模型(如图 5(左)所示),另一种是更深层的残差模型(如图 5(右)所示)。
图 5. 模型架构。左图:浅层架构,2 个卷积层,120 万个参数。右图:深层架构,15 个卷积层和 160 万个参数高吞吐量、计算效率和可扩展性是 IMPALA 的主要设计目标。为了证明 IMPALA 在这些指标上优于当前算法,作者比较了 A3C、batched A2C 变体和经过各种优化的 IMPALA 变体。在使用 GPU 的单机实验中,在前向传递中使用动态批处理,以避免多次批处理大小为 1 的前向传递。动态批处理模块由专门的 TensorFlow 操作实现,但在概念上与 A3C 中使用的队列类似。表 1 详细列出了采用图 5 中浅层模型的单机版和多机版的结果。在单机情况下,IMPALA 在这两项任务上都取得了最高性能,超过了所有 batched A2C 变体,也超过了 A3C。然而,在分布式多机设置中,IMPALA 才能真正展示其可扩展性。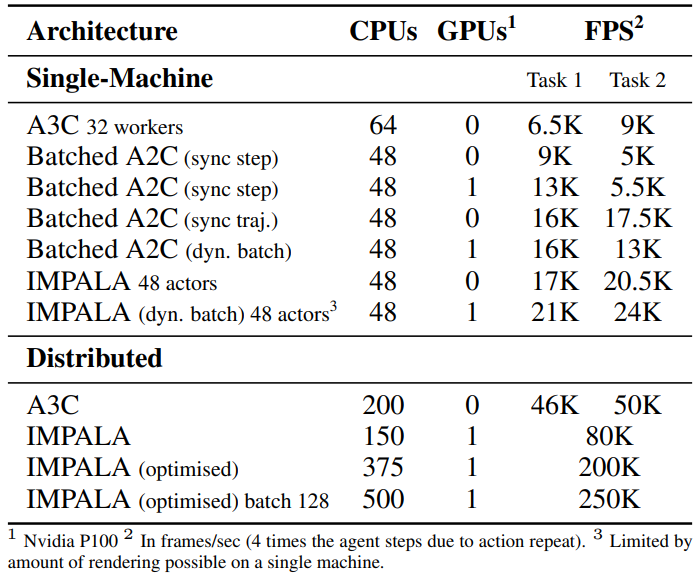
表 1. 图 5 所示的浅层模型在 seekavoid_arena_01(任务 1)和 rooms keys doors puzzle(任务 2)上的吞吐量。后者有长度可变的 episodes 和缓慢的 restarts。如果没有特别说明,batched A2C 和 IMPALA 使用的批处理大小为 32图 6 给出了 IMPALA、A3C 和 batched A2C 与图 5 中浅层模型的比较。在所有 5 个任务中,batched A2C 或 IMPALA 都能获得最佳的最终平均奖励,而且在整个训练过程中,除了 seekavoid_arena_01 以外,它们在所有任务中都领先于 A3C。在 5 项任务中,IMPALA 有 2 项优于 synchronous batched A2C,同时吞吐量也高得多(见表 1)。作者假设,这种情况可能是由于 V-trace 偏离策略校正的作用类似于广义优势估计和异步数据收集,从而产生了更多样化的经验批次。
图 6. 上行:在 5 个 DeepMind 实验室任务上进行单任务训练。每条曲线都是基于最终奖励的最佳 3 次运行的平均值。IMPALA 的性能优于 A3C。下行:不同超参数组合的稳定性,按不同超参数组合的最终性能排序。IMPALA 始终比 A3C 更稳定IMPALA 的高数据吞吐量和数据效率使我们只需对训练设置做最小的改动,就能并行训练一个任务和多个任务。在多任务套件中,作者不在所有参与者上运行相同的任务,而是为每个任务分配固定数量的参与者。请注意,模型并不知道它是在哪个任务上进行训练或评估的。为了测试 IMPALA 在多任务环境中的性能,作者使用了 DMLab-30,这是一套基于 DeepMind Lab 的 30 种不同任务。在该套件的众多任务类型中,包括带有自然地形的视觉复杂环境、带有基础语言的指令型任务、导航任务、认知任务和以脚本机器人为对手的第一人称标记任务。有关 DMLab-30 和任务的详细介绍,可访问 github.com/deepmind/lab 和 deepmind.com/dm-lab-30。作者将 IMPALA 的多个变体与分布式 A3C 实现进行了比较。除了使用基于群体训练(population based training,PBT)的 agent 外,所有 agent 都在相同范围内进行超参数扫描训练。作者报告的是 mean capped humannormalised score,其中每个任务的得分上限为 100%。使用 mean capped humannormalised score 强调了解决多个任务的必要性,而不是专注于在单一任务上成为 super human。对于 PBT,作者使用 mean capped humannormalised score 作为适应度函数,并调整熵成本、学习率和 RMSProp ε。作者特别比较了以下 agent 变体:A3C,deep、分布式实现,由 210 个 worker(每个任务 7 人)组成的分布式实施系统,采用深度残差网络架构(图 5(右));IMPALA,浅层,210 个 actors;IMPALA,深层,150 个 actors,都只有一个 learner;IMPALA,deep,PBT,与 IMPALA,deep 相同,但额外使用 PBT 进行超参数优化;IMPALA,深度,PBT,8 learners,它利用 8 个 learner GPU 来最大限度地提高学习速度。作者还在专家设置中训练 IMPALA agent,即 IMPALA-Experts,deep,其中每个任务训练一个单独的 agent。在这种情况下,作者没有为每个任务单独优化超参数,而是对 30 个专家 agent 接受训练的所有任务进行优化。表 2 和图 7 显示,所有 IMPALA 变体的性能都远远优于深度分布式 A3C。此外,IMPALA 的深度变体不仅在最终性能方面,而且在整个训练过程中都比浅层版本表现得更好。表 2 显示,虽然 IMPALA、deep、PBT 的 8 个 learner 提供了更高的吞吐量,但其最终性能与 1 GPU 的 IMPALA、deep、PBT 在相同步数下的性能相同。特别重要的是,IMPALA 专家对每个任务进行单独训练,而 IMPALA deep PBT 则对所有任务进行一次性训练,两者之间的差距非常明显。
表 2. DMLab-30 的 mean capped humannormalised score。所有模型都在测试任务中进行了评估,每个任务有 500 个 episodes。表中显示了每个架构的最佳得分
图 7. 在 DMLab-30 任务集的训练过程中,每个 sweep/population 中的最佳 agent 在所有环境下的数据消耗表现。采用多任务训练的 IMPALA 不仅速度更快,而且在所有 30 个任务中的收敛精度更高,数据效率更高。x 轴是由 24 个 agent 组成的超参数 sweep/PBT population 中一个 agent 所消耗的数据,整个 population/sweep 所消耗的总数据可通过乘以 population/sweep 大小获得2.2 IMPACT: Importance Weighted Asynchronous Architectures with Clipped Target Networks [3]
IMPACT 是由来自 UC Berkeley AMPLab 的研究人员所提出。AMPLab(Algorithms, Machines, and People)是 UC Berkeley 的大数据实验室。AMPLab 身兼实验室和孵化器的双重身份,成为了学术界与工业界跨界典范。它有 Spark、Alluxio、Mesos 等熠熠生辉的孵化成果。关于 IMPACT 的研究成果发表在 ICLR 2020 中。ICLR 是深度学习方面的顶级会议,ICLR 2020 在埃塞俄比亚首都亚的斯亚贝巴举办,最终 2594 篇论文中共有 687 篇被接收,录取率为 26.5%经典强化学习 agent 的实际使用往往受到训练时间的限制。为了加速训练,转而提出了分布式强化学习架构来并行化及加速训练过程。上文介绍的 IMPALA 可以实现更高的吞吐量,因为它可以异步收集 workers 的样本。但是,IMPALA 的采样效率较低,因为它无法像 PPO 那样安全地在每个批次采取多个 SGD 步骤。因此,随着样本吞吐量的不断增加,样本的学习效率往往会下降。为解决这个问题,本文提出了经典的 IMPACT(Importance Weighted Asynchronous Architectures with ClippedTarget Networks),从三个方面扩展了 IMPALA:- 用于稳定 agent 目标的 target network
在离散环境中,IMPACT 获得了更高的奖励,与 IMPALA 相比,训练时间减少 30%,在连续环境中,比现有的可扩展 agent 训练更快,同时保持同步 PPO 的样本效率(样本的学习质量)。
图 8. 分布式 PPO、IMPALA 和 IMPACT 的架构方案。PPO 将 worker batches 聚合到一个大的训练批次中,learner 执行小批量 SGD。IMPALA worker 异步生成数据。IMPACT 由一个批次缓冲区组成,该缓冲区接收 worker 的经验和目标对经验的评估。learner 从缓冲区中采样与 IMPALA 一样,IMPACT 将采样 worker 与学习 worker 分开。算法 1 和图 8c 描述了 IMPACT 的主要训练循环和架构。一开始,每个 worker 从主网络复制权重。然后,每个 worker 使用自己的策略收集轨迹,并将数据(s_t、a_t、r_t)发送到 circular buffer 中。与此同时,worker 也会异步从主 learner 中提取策略权重。在此期间,目标网络每迭代 t_target 次就会与主 learner 同步一次。然后,主 learner 从 circular buffer 中反复汲取经验。每个样本的权重都是按照 π_θ/π_worker_i 以及与目标网络比率相匹配 π_worker_i/π_target。目标网络用于提供一个稳定的信任区域(图 9),即使在异步设置(即 IMPALA 架构)中也能实现每批多个步骤(如 PPO)。

图 9. 在异步 PPO 中,有多个候选策略可以用来定义信任区域:(1) π_worker_i,即产生这批经验的 worker 进程的策略;(2) π_learner,learner 进程的当前策略;(3) π_target,目标网络的策略。引入目标网络后,既能形成稳定的信任区域,又能在每批经验中异步收集多个 SGD 步骤,从而提高采样效率。由于 worker 可以从其主策略副本中异步生成经验,因此也能实现良好的实时效率2.2.1 MAXIMAL TARGET-WORKER CLIPPINGPPO 从上一次迭代的策略 π_θ_old 中收集经验,并通过重要性采样 off-policy 经验来训练当前策略与 π_θ 的关系。在异步设置中,worker i 的策略(记为 π_worker_i)为策略网络 π_θ 生成经验。批次 B 来自 worker i 的概率可被参数化为分类分布 i ∼ D(α_1, ..., α_n)。作者通过在重要性取样策略梯度目标(IS-PG)中添加一个额外的期望值来实现这一点:
由于每个 Worker 都包含不同的策略,因此 agent 会引入一个目标网络以保持稳定(图 9)。off-policy agent(如 DDPG 和 DQN)用移动平均法更新目标网络。对于 IMPACT,会定期用主网络更新目标网络。但是,如图 10 所示,使用重要性加权比率 π_θ/π_target 进行训练会导致数值不稳定。为了避免这种情况,作者将 worker 策略 π_worker_i 与目标策略 π_target 的重要性采样比率进行了剪切(Clipping):
当主网络的 action distribution 在几次训练迭代中发生显著变化时,worker i 的策略 π_worker_i 会采样目标策略 π_target 以外的数据,从而导致较大的似然比 π_worker_i/π_target 。剪切函数 min ( π_worker_i/π_target, ρ) 会将较大的 IS 比率拉回到 ρ。
图 10. 对照基准消融研究的训练曲线。在 (a) 中,IMPACT 目标优于其他可能的替代损失比率选择:R_1 =πθ/π_target, R_2 =πθ/πworker_i, R_3 =πθ max (π_target,βπ_worker_i)。(b) 中展示了目标网络更新频率对一系列选择的稳健性。尝试将目标网络更新频率 t_target 设为 n = N - K 的倍数(从 1/16 到 16 不等),即 circular buffer 大小与缓冲区中每批次 replay 时间的乘积当 ρ > 1 时,剪切后的目标比率会更大,从而增强优势估计值 Aˆt。这将激励 agent 采取好的行动,同时避免坏的行动。因此,ρ 值越大,agent 学习速度越快,但代价是不稳定。作者引入带有 V-trace 的 GAE-λ。V-trace GAE-λ 通过在 TD 误差求和中添加剪切重要度采样项来修改优势函数:
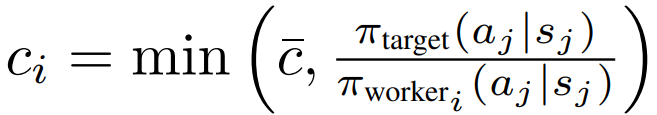
IMPACT 使用循环缓冲器 circular buffer(图 11)来模拟标准 PPO 使用的 mini-batch SGD。Circular Buffer 存储 N 个批次,最多可遍历 K 次。在遍历 K 次后,一个批次将被丢弃,由一个新的 worker batch 取代。
图 11. (a): Circular Buffer 简述:N 和 K 分别对应缓冲区大小和每个批次的最大遍历次数。旧批次由 worker 生成的批次取代。(b): IMPACT 在不同 K 条件下的时间性能。(c): 不同 K 的 IMPACT 在时间步长方面的性能。K = 2 在时间上优于所有其他设置,并且比 K = 1、4、16、32 更有效率为了激励 learner,Circular Buffer 和目标网络类似于 PPO π_old 经验中的 mini batch。当目标网络的更新频率 n = NK 时,当 learner 在 K 次 SGD iterations 中采样 N 个 mini batch 时,Circular Buffer 相当于分布式 PPO 的训练批次。这与 ACER 和 APE-X 等标准 replay buffer 不同,在 ACER 和 APE-X 中,过渡(s_t、a_t、r_t、s_t+1)要么是统一采样,要么是根据优先级采样,当缓冲区满时,将丢弃最旧的 transitions。图 11 举例说明了调整 K 可以提高训练样本效率和减少训练 wall-clock time 的经验。1. 与之前的研究相比,target-clipping objective 对 agent 的性能有何影响?2. IMPACT 循环缓冲区对采样效率和训练壁钟 (wall-clock) 时间有何影响?3. 在采样和实时性能方面,IMPACT 与 PPO 和 IMPALA 基线相比如何?4. IMPACT 如何根据 worker 数量进行扩展?2.2.3.1 TARGET CLIPPING PERFORMANCE作者研究了 clipped-target objective 相对于先前工作(包括基于 PPO 和 IS-PG 的目标)的性能。具体来说,作者考虑了以下比率:
在所有三个实验中,使用 PPO 的 clipping function 截断所有三个比率:c (R) = clip (R, 1- ε, 1+ ε) 并在异步设置下进行训练。图 11 (a) 揭示了两个重要的启示:首先,R1 的性能在训练中途会突然下降。其次,R2 性能不佳。作者推测,R1 的失败是由于目标网络和 worker 网络不匹配造成的。在主 learner 发生剧烈变化的训练期间,worker 的行动输出与 learner 的输出大相径庭,导致行动概率较小。这就在训练中产生了很大的比率,破坏了训练的稳定性。此外,R2 的失败是由于不同的 worker 从多个方向推拉 learner 造成的。learner 在没有建立起适当信任区域的情况下,会根据最新 worker 的建议前进,从而导致许多 worker 的建议相互冲突。损失函数 R3 表明,clipping 是必要的,有助于促进训练。通过限制目标与 worker 的比例,我们可以确保该比例不会爆炸,也不会破坏训练的稳定性。此外,通过目标网络提供单一指导,还能防止 worker 提出相互破坏的建议。在图 11(b)中,作者测试了 n 的不同数量级的更新频率。作者发现 agent 性能对不同的频率是稳健的。当 n = 1 ∼ 4 时,agent 不学习。根据经验结果,作者推测只要能形成稳定的信任区域,agent 就能进行训练。反之,如果更新频率过低,agent 就会在同一信任区域反复多次,从而影响学习速度。当 K 增加时,时间和采样效率之间的权衡并不一定成立。图 11b 和 11c 显示,IMPACT 通过在高采样吞吐量和采样效率之间取得平衡,实现了更大的奖励。当 K = 2 时,IMPACT 在时间和采样效率方面都表现最佳。本文结果表明,wall-clock time 和采样效率可以根据 circular buffer 中 K 值的调整进行优化。作者在三个连续环境中测试了 agent(图 12):在 16 个 CPU 和 1 个 GPU 上测试了 HalfCheetah、Hopper 和 Humanoid。策略网络由两层 256 个单元的全连接层组成,具有非线性激活 tanh。critic 网络与策略网络采用相同的架构。为了保持一致性,PPO、IMPALA 和 IMPACT 采用了相同的网络架构。对于离散环境(图 13),作者选择了 Pong、SpaceInvaders 和 Breakout 作为分布式 RL 库中的常用基准。这些实验在 32 个 CPU 和 1 个 GPU 上运行。策略网络由三个 4x4 层和一个 11x11 conv 层组成,采用非线性激活 ReLU。critic 网络与策略网络共享权重。网络的输入是由四幅 42x42 下采样的 Atari 环境图像组成的堆栈。图 12 和图 13 显示了 IMPACT、IMPALA 和 PPO 的总平均评估奖励率。作者在每种环境下使用三种不同的随机种子对每种算法进行了总计三个小时的训练。根据实验结果,IMPACT 在离散域和连续域的训练速度都比 PPO 和 IMPALA 快得多,同时样本效率与 PPO 相同或更好。
图 12. 在连续控制域方面,IMPACT 的采样效率和时间效率均优于基线:Hopper、Humanoid、HalfCheetah
图 13. 在离散控制域方面,IMPACT 的实时性和采样效率均优于 PPO 和 IMPALA:Breakout、SpaceInvaders 和 Pong结果表明,IMPACT 的连续控制任务对 circular buffer 的元组 (N, K) 非常敏感。N = 16 和 K = 20 是连续控制的稳健选择。虽然较高的 K 抑制了 worker 的采样吞吐量,但 replaying experiences 提高了采样效率,从而在总体上减少了训练 wall clock 时间,并获得了更高的奖励。最后,图 14 显示了 IMPACT 的性能如何随 worker 数量的增加而变化。更多的 worker 意味着样本吞吐量的增加,这反过来又增加了训练吞吐量(learner 消耗批次的速度)。随着 learner 每秒消耗更多的 worker 数据,IMPACT 可以在更短的时间内获得更好的性能。然而,随着 learner 数量的增加,观察到的性能提升开始下降。
图 14. 在连续和离散控制任务中,IMPACT 在 worker 数量方面的表现2.3 SEED RL: SCALABLE AND EFFICIENT DEEP-RL WITH ACCELERATED CENTRAL INFERENCE [4]
SEED (scalable, Efficient Deep-RL) 是谷歌 Brain Team 提出的一个能够扩展到数千台机器的强化学习架构。相关内容也发表在 ICLR 2020 中。通过有效利用加速器,SEED 不仅可以每秒进行数百万帧的训练,而且还可以降低实验成本。作者通过一个简单的架构来实现这一点,该架构具有集中推理和优化的通信层。SEED 采用两种最先进的分布式算法,IMPALA/V-trace (策略梯度) 和 R2D2 (Q-learning),并在 Atari-57、DeepMind Lab 和 Google Research Football 上进行评估。相较于已有的工作,作者提升了 Football 游戏的表现,并且能够将 Atari-57 上的最先进技术提高三倍的时间。Github: http://github.com/google-research/seed_rl。
在介绍 SEED 的架构之前,作者首先分析了 IMPALA 所使用的通用角色 learner 架构,该架构也以各种形式用于 Ape-X、OpenAI Rapid 和其他系统。图 15a 是该架构的概览。大量 actors 重复从 learner(或参数服务器)读取模型参数。然后,每个 actor 利用本地模型对行动进行采样,并生成观察、行动、策略对数 / Q 值的完整轨迹。最后,该轨迹连同循环状态被传输到共享队列或 replay buffer。learner 以异步方式从队列 /replay buffer 读取成批轨迹,并优化模型。造成这种架构不完善的原因有很多:- 使用 CPU 进行神经网络推理:actor 通常使用 CPU(偶尔在昂贵的环境中使用 GPU)。众所周知,CPU 对神经网络的计算效率较低。当模型的计算需求增加时,用于推理的时间开始超过环境 step 计算的时间。解决方法是增加 actor 的数量,但这会增加成本并影响收敛性。
- 资源利用效率低:Actor 需要在两个任务(环境 step 和网络推理)之间进行切换。这两项任务的计算要求往往不尽相同,从而导致资源利用率低或 actor 运行速度慢。例如,有些环境本身是单线程的,而神经网络则很容易并行化。
- 带宽要求:actors 和 learners 之间需要传输模型参数、循环状态和观测结果。相对于模型参数,观测轨迹的大小往往只占几个百分点。此外,基于内存的模型会发送大量状态,从而增加带宽需求。
虽然 GA3C 和单机 IMPALA 等单机方法避免了使用 CPU 进行推理,也没有网络带宽要求,但它们受到资源使用和多种环境所需规模的限制。SEED 采用的架构(图 15b)解决了上述问题。推理和轨迹积累被转移到 learner 身上,这使得它在概念上成为一个具有远程环境(除了处理故障)的单机设置。移动逻辑可有效地使 actor 在环境中形成一个小循环。在每一个环境 step 中,观察结果都会被发送到 learner,由 learner 进行推理并将行动反馈给 actor。这就带来了一个新问题:延迟。为了尽量减少延迟,作者创建了一个使用高性能 RPC 库 gRPC(grpc.io)的简单框架。具体来说,采用了流式 RPC,在这种情况下,actor 与 learner 之间的连接保持开放,元数据只发送一次。此外,该框架包含一个批处理模块,可将多个 actor 推理调用有效地批处理在一起。在 actor 与 learner 可以在同一台机器上运行的情况下,gRPC 使用 unix 域套接字,从而减少了延迟、CPU 和系统调用开销。总的来说,对于我们考虑的一些模型,端到端延迟(包括网络和推理)更快。IMPALA 和 SEED 架构的不同之处在于,对于 SEED 来说,在任何时间点都只存在一个模型副本,而对于分布式 IMPALA 来说,每个 actor 都有自己的副本。这就改变了轨迹偏离策略的方式。在 IMPALA 中(图 16a),actor 在整个轨迹中使用相同的策略 π_θ_t。对于 SEED(图 16b)来说,轨迹展开过程中的策略可能会多次改变,后面的步骤会使用与优化时更接近的最新策略。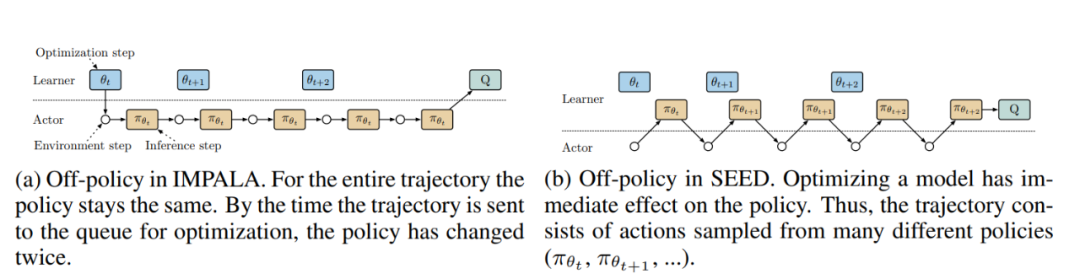
图 16. 在异步优化模型参数 θ 的同时评估策略 π 时的 "near on-policy" 变体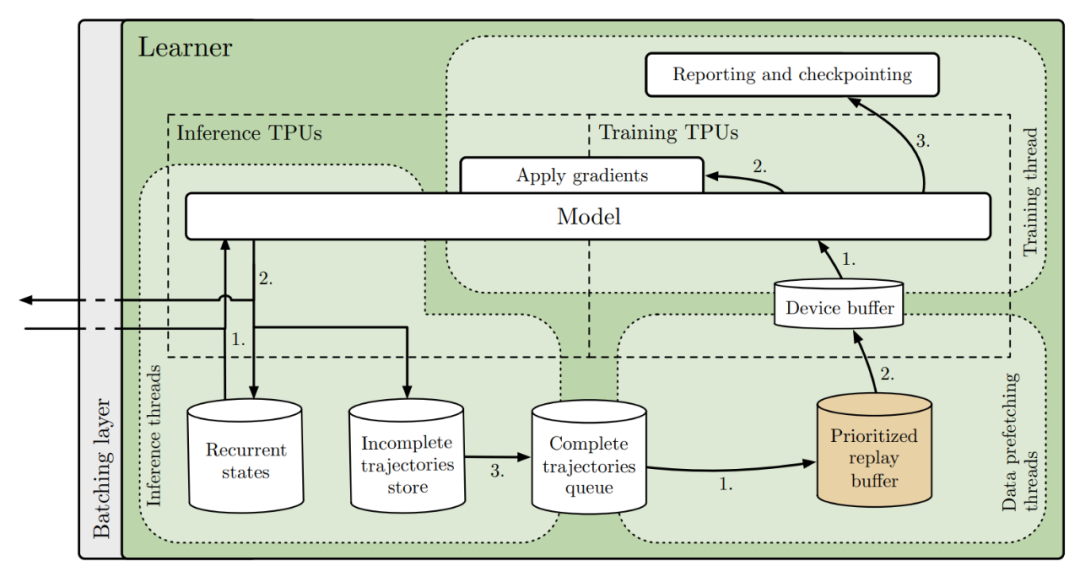
图 17. SEED 中详细的 learner 架构(可选择 replay buffer)SEED 架构中 learner 的详细视图如图 17 。共运行三种线程:1. 推理 2. 数据预取 3. 训练。推理线程接收一批观测数据、奖励和事件终止标志。它们加载循环状态,并将数据发送到推理 TPU 内核。收到采样动作和新的循环状态后,动作会被发送回 actors,同时存储最新的循环状态。当轨迹完全展开后,它会被添加到 FIFO 队列或 reply buffer,随后由数据预取线程进行采样。最后,轨迹被推送到参与训练的每个 TPU 内核的设备缓冲区。训练线程(Python 主线程)接收预取的轨迹,使用训练 TPU 内核计算梯度,并将梯度同步应用于所有 TPU 内核的模型(推理和训练)。1. 将推理转移到 learner 中,从而消除 actor 中任何与神经网络相关的计算。在这种架构中,增加模型规模不会增加对更多 actor 的需求(事实上恰恰相反)。2. 在 learner 上分批进行推理,并在 actor 上设置多个环境。这样可以充分利用 learner 上的加速器和 actor 上的 CPU。用于推理和训练的 TPU 内核数量可根据推理和训练工作量进行微调。所有这些因素都有助于降低实验成本。3. 所有涉及模型的内容都会保留在 learner 上,只有观察结果和操作会在 actor 和 learner 之间发送。这可减少高达 99% 的带宽需求。4. 使用延迟最小、开销最小的流式 gRPC,并将批处理集成到服务器模块中。作者提供了以下两种在 SEED 框架中实现的算法:V-trace 和 Q-learning。适应该框架的算法之一是 V-trace [5]。我们不包括在 IMPALA 基础上提出的任何附加功能。这些附加功能也可应用于 SEED,由于它们的计算成本较高,因此将受益于 SEED 架构。作者通过实施 R2D2 这一最先进的基于价值的分布式 agent [6],展示了 SEED 架构的多功能性。R2D2 本身建立在一长串对 DQN 的改进之上:double q-learning、multi-step bootstrap targets、dueling 网络架构、prioritized distributed replay buffer、价值函数重缩放、LSTM 和 burn in。作者证明,可以通过直接灵活的实现方式,在 learner 上保留 reply buffer,而不是分布式 reply buffer。这样就可以在设置中取消一种作业,从而降低复杂性。它的缺点是受 learner 内存的限制,但在本文实验中,这在很大程度上不是问题:reply 105 个长度为 120 的轨迹缓冲区,其中包含 84 × 84 个未压缩灰度观测值(遵循 R2D2 的超参数),需要 85GB 内存,而谷歌云可提供数百 GB 内存。不过,在需要更大 reply buffer 的情况下,使用分布式 reply buffer 和 SEED 的中央推理也是可行的。作者在多个环境中对 SEED 进行了评估:DeepMind Lab、Google Research Football 和 Arcade 学习环境。在这里,我们详细介绍 DEEPMIND LAB AND V-TRACE 的实验情况,其它环境中的实验结果可见原文。DeepMind Lab 是一个基于 Quake 3 引擎的 3D 环境。它包含迷宫、激光枪战和记忆任务。作者对四个常用任务进行了评估。使用的动作集来自文献 [7],但对于某些任务,使用更大的动作集可以获得更高的奖励率。在所有实验中,我们使用的动作重复次数为 4,图中的帧数被列为环境帧(相当于步骤数的 4 倍)。两个 agent 使用了相同的 24 个超参数集和相同的模型(IMPALA 的 ResNet)。第一个实验评估了图 16 中描述的 off policy 行为变化的影响。IMPALA 和 SEED 使用了完全相同的超参数,包括使用的环境数量。如图 17 所示,SEED 的超参数稳定性略好于 IMPALA,而最终奖励略高。
图 17. IMPALA 和 SEED 在完全相同的条件下(175 个 actor、相同的超参数等)的比较,图中显示的超参数组合按不同超参数组合的最终性能排序为了评估性能,作者比较了使用 Nvidia P100 和 SEED 的 IMPALA 与多种加速器设置。它们在同一组超参数上进行评估。作者发现,在使用 2 个 TPU v3 内核时,SEED 比 IMPALA 快 2.5 倍(见表 3),而使用的环境仅多 77%,CPU 仅少 41%。在样本复杂度保持不变的情况下,从 2 个内核扩展到 8 个内核,速度提高了 4.4 倍(图 18)。
表 3. SEED、IMPALA 和 R2D2 的性能
图 18. 4 项 DeepMind 实验室任务的训练。每条曲线都是按照 [7] 中的评估程序,根据最终奖励计算出的 24 次运行中的最佳结果。样本复杂度最高保持在 8 TPU v3 内核,这使得训练速度比 IMPALA 基线快 11 倍。上行:X 轴为每帧(帧数 = 4x 步数)。下行:X 轴为小时数由于使用 6 个内核进行训练和 2 个内核进行推理,而不是每个内核 1 个,因此速度提高了 4 倍以上,从而提高了利用率。但与相关研究相反,作者发现,即使采用预热和 actor de-correlation 等方法,增加批大小也会损害样本复杂性。作者猜测,这是由于 DeepMind 实验室任务中的 actor 和环境多样性有限。使用 Nvidia P100 时,SEED 比 IMPALA 慢 1.58 倍。由于 SEED 是在加速器上执行推理,因此速度变慢是意料之中的。不过,SEED 使用的 CPU 明显更少,成本也更低。TPU 版本的 SEED 已经过优化,但使用 P100 的 SEED 可能会有改进。在这篇文章中,我们主要介绍了一些经典的分布式强化学习架构,基本为 IMPALA 及其后续改进的方法,主要思路是:使用异步架构,在提升样本吞吐量的同时,引入一些 off-policy 修正。这一类方法的共同问题是:由于算法不再满足 on-policy 要求,导致单位样本效率降低,甚至可能会影响最终的收敛效果。除了这一类方法,经典的分布式强化学习架构还有:使用同步架构,保证算法满足 on-policy 要求,例如 Batched A2C 和 DD-PPO,以及,在计算梯度的时候保证 on-policy 特性,但是用异步的方式更新梯度,例如 A3C 和 APPO 等等。这些方法也存在整体吞吐量不佳、模型收敛性不好等问题。这几年在分布式强化学习领域涌现了大量优秀的工作。它们从不同角度出发,针对分布式强化学习特点,提出了许多解决方案,来不断提升算法和框架的能力。从最初需要几十个小时甚至十多天才能在 Atari 游戏上达到人类玩家水平,到目前被缩短到几小时甚至几分钟以内。分布式强化学习正处在一个蓬勃发展的时期,我们将在 part 2 介绍一些最新的研究进展。[1] Distributed Deep Reinforcement Learning: A Survey and A Multi-Player Multi-Agent Learning Toolbox, https://arxiv.org/pdf/2212.00253.pdf[2] IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architecture,https://arxiv.org/pdf/1802.01561.pdf[3] IMPACT: Importance Weighted Asynchronous Architectures with Clipped Target Networks,https://arxiv.org/pdf/1912.00167.pdf[4] SEED RL: SCALABLE AND EFFICIENT DEEP-RL WITH ACCELERATED CENTRAL INFERENCE,https://arxiv.org/pdf/1910.06591.pdf[5] Lasse Espeholt, Hubert Soyer, Rémi Munos, Karen Simonyan, Volodymyr Mnih, Tom Ward, Yotam Doron, Vlad Firoiu, Tim Harley, Iain Dunning, Shane Legg, and Koray Kavukcuoglu. IMPALA: scalable distributed deep-rl with importance weighted actor-learner architectures. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018, pp. 1406–1415, 2018. URL http: //proceedings.mlr.press/v80/espeholt18a.html.[6] Steven Kapturowski, Georg Ostrovski, John Quan, Remi Munos, and Will Dabney. Recurrent experience replay in distributed reinforcement learning. 2018.[7] Lasse Espeholt, Hubert Soyer, Rémi Munos, Karen Simonyan, Volodymyr Mnih, Tom Ward, Yotam Doron, Vlad Firoiu, Tim Harley, Iain Dunning, Shane Legg, and Koray Kavukcuoglu. IMPALA: scalable distributed deep-rl with importance weighted actor-learner architectures. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018, pp. 1406–1415, 2018. URL http: //proceedings.mlr.press/v80/espeholt18a.html.
关于机器之心全球分析师网络 Synced Global Analyst Network
机器之心全球分析师网络是由机器之心发起的全球性人工智能专业知识共享网络。在过去的四年里,已有数百名来自全球各地的 AI 领域专业学生学者、工程专家、业务专家,利用自己的学业工作之余的闲暇时间,通过线上分享、专栏解读、知识库构建、报告发布、评测及项目咨询等形式与全球 AI 社区共享自己的研究思路、工程经验及行业洞察等专业知识,并从中获得了自身的能力成长、经验积累及职业发展。
感兴趣加入机器之心全球分析师网络?点击阅读原文,提交申请。